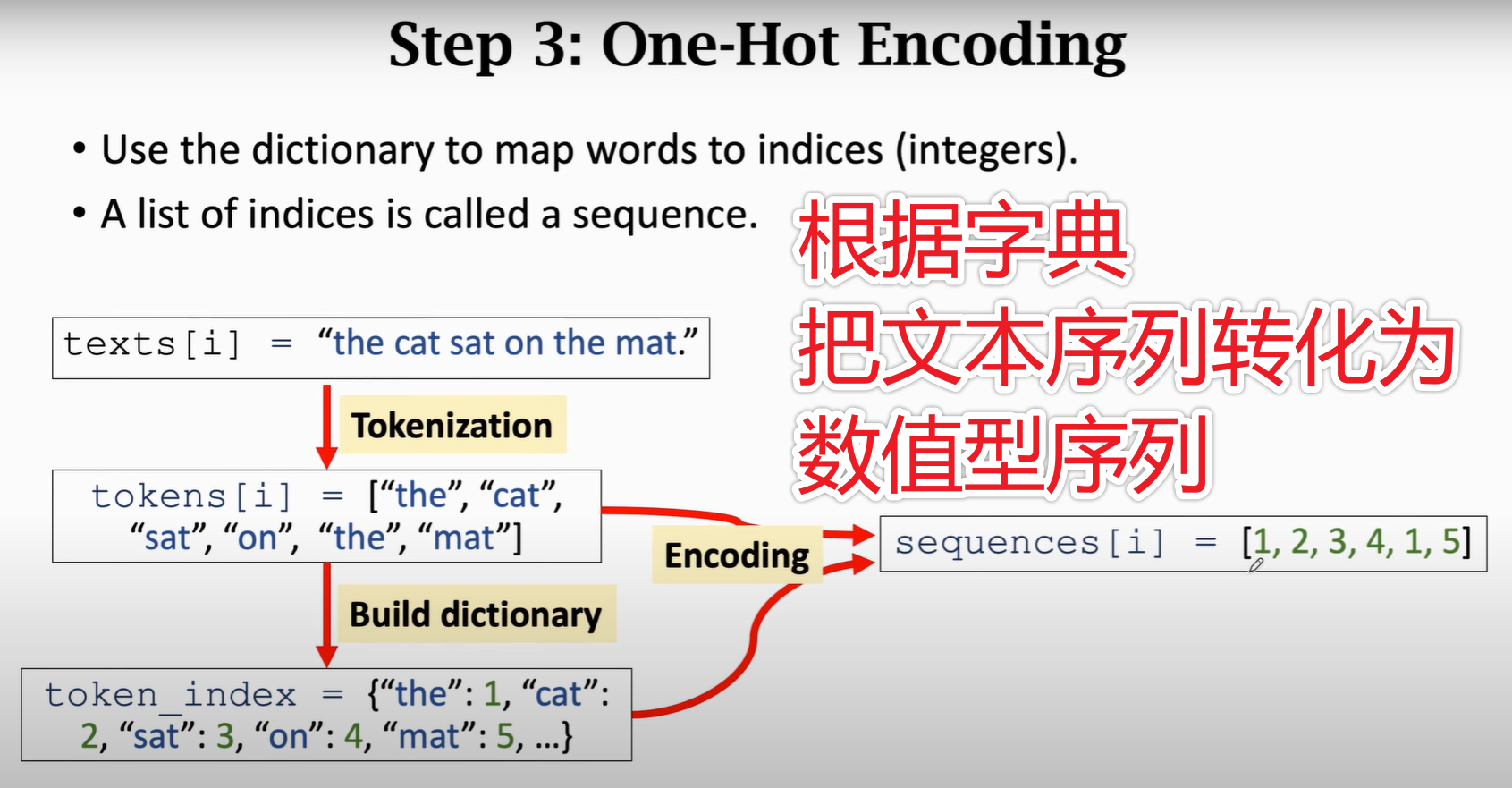
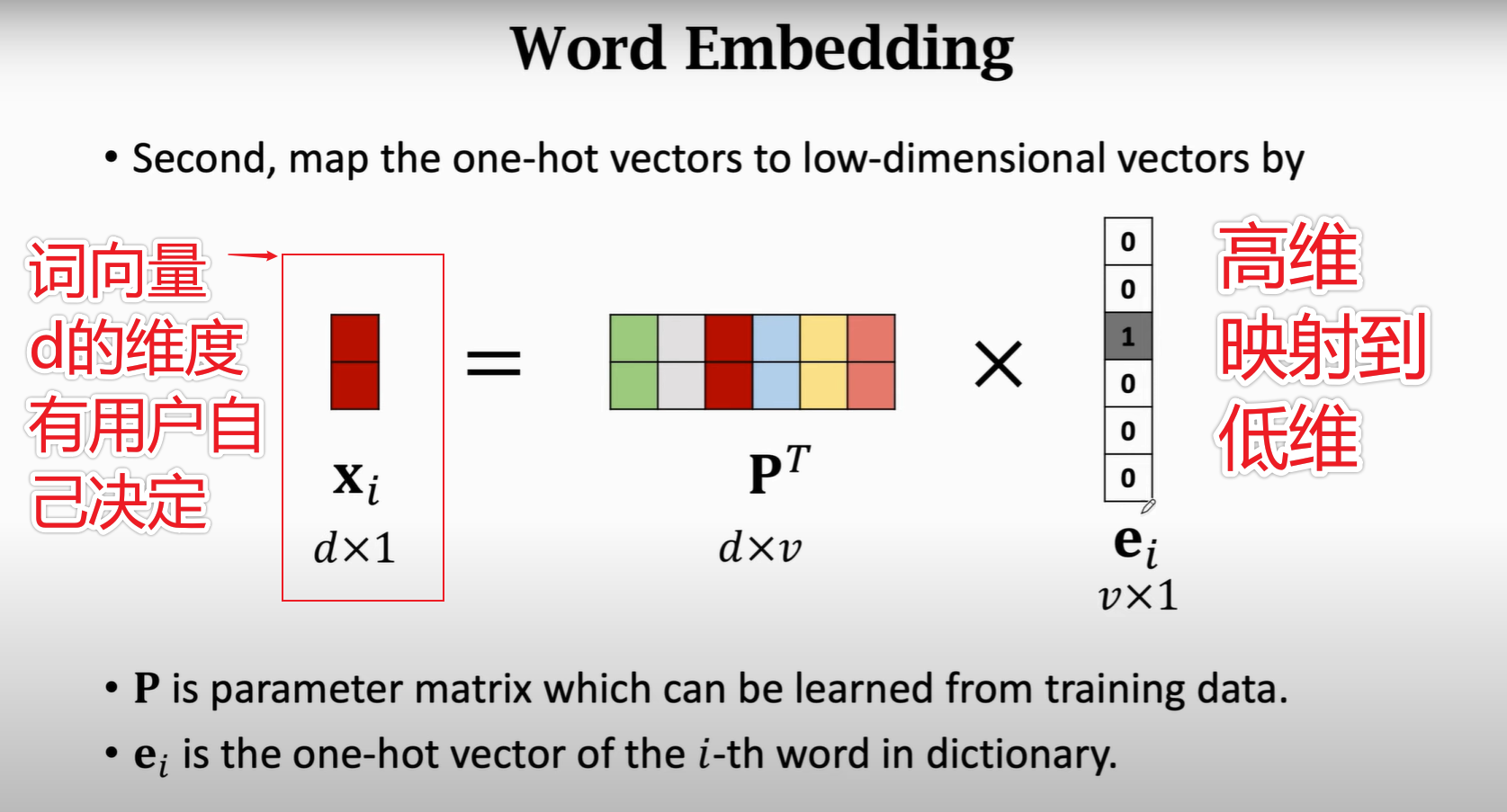
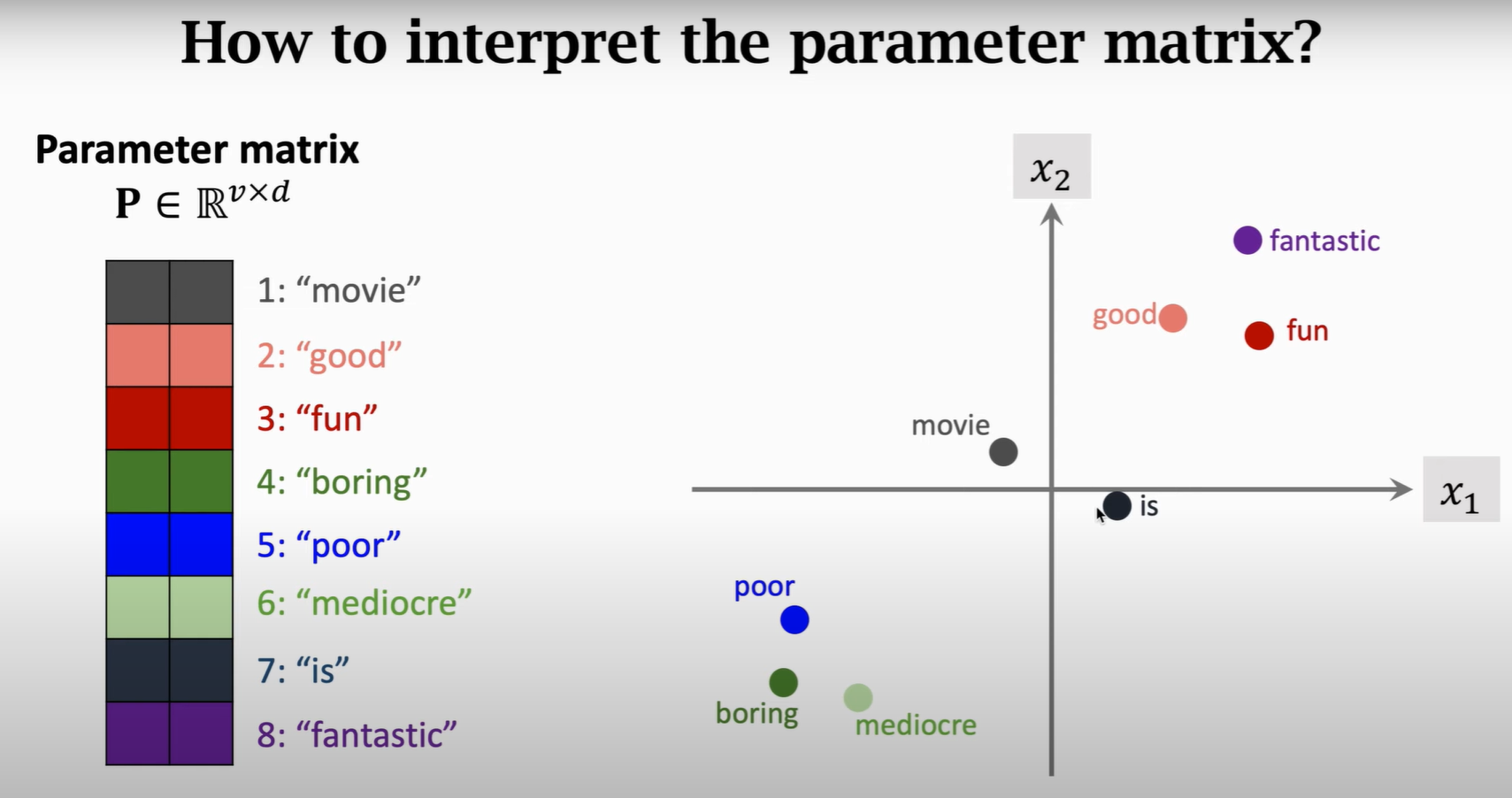
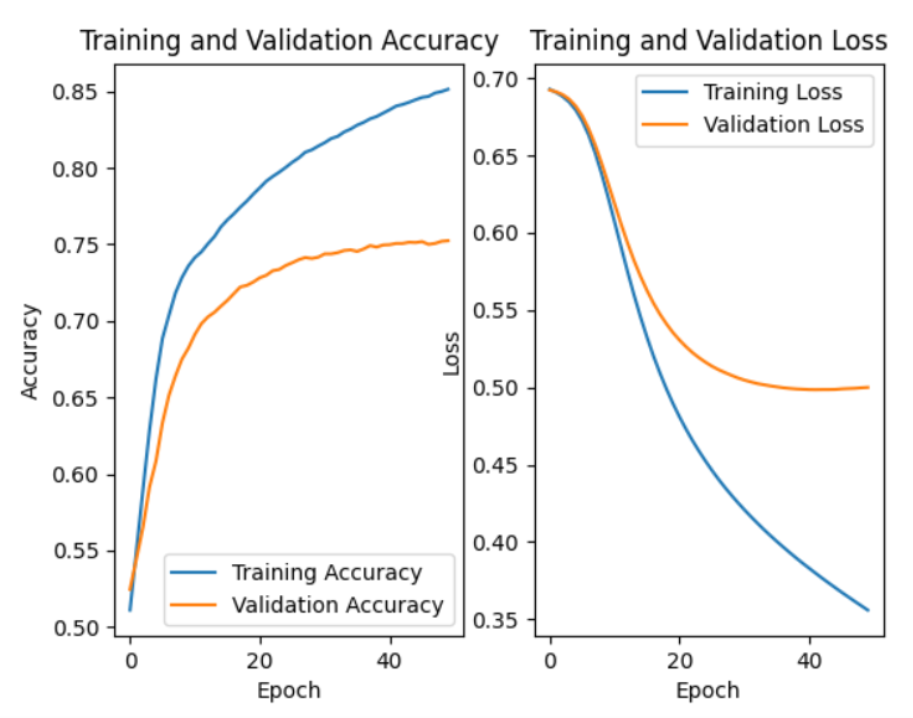
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| CONTEXT_SIZE = 2
EMBEDDING_DIM = 10
test_sentence = """When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty's field,
Thy youth's proud livery so gazed on now,
Will be a totter'd weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv'd thy beauty's use,
If thou couldst answer 'This fair child of mine
Shall sum my count, and make my old excuse,'
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel'st it cold.""".split()
trigram = [((test_sentence[i],test_sentence[i+1]),test_sentence[i+2])
for i in range(len(test_sentence)-2)
]
vocb = set(test_sentence)
word_to_idx = {word:i for i,word in enumerate(vocb)}
idx_to_word = {word_to_idx[word]: word for word in word_to_idx}
print(word_to_idx)
import torch
from torch import nn
import torch.nn.functional as F
from torch.autograd import Variable
from torch.nn.modules.activation import Sigmoid
class n_gram(nn.Module):
def __init__(self,vocab_size,context_size=CONTEXT_SIZE,n_dim=EMBEDDING_DIM):
super(n_gram,self).__init__()
self.embed = nn.Embedding(vocab_size, n_dim)
self.classify = nn.Sequential(
nn.Linear(context_size * n_dim, 64),
nn.ReLU(),
nn.Linear(64, vocab_size)
)
def forward(self, x):
voc_embed = self.embed(x)
voc_embed = voc_embed.view(1, -1)
out = self.classify(voc_embed)
return out
net = n_gram(len(word_to_idx))
word = trigram[0][0]
label = trigram[0][1]
print(word)
print(label)
word = Variable(torch.LongTensor([word_to_idx[i] for i in word]))
print(word)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2, weight_decay=1e-5)
for e in range(100):
train_loss = 0
for word, label in trigram:
word = Variable(torch.LongTensor([word_to_idx[i] for i in word]))
label = Variable(torch.LongTensor([word_to_idx[label]]))
out = net(word)
loss = criterion(out, label)
train_loss += loss.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 10 == 0:
print('epoch: {}, Loss: {:.6f}'.format(e + 1, train_loss / len(trigram)))
net = net.eval()
count = 0
for i in range(len(trigram)):
word, label = trigram[i]
word = Variable(torch.LongTensor([word_to_idx[i] for i in word]))
out = net(word)
pred_label_idx = out.argmax(1)
predict_word = idx_to_word[pred_label_idx.item()]
print(f'real word is {label}, predicted word is {predict_word}.')
if label == predict_word:
count += 1
print(f'Accuracy is {count/len(trigram)}')
|