类比:
-
训练集相当于上课学知识
-
验证集相当于课后的的练习题,用来纠正和强化学到的知识
-
测试集相当于期末考试,用来最终评估学习效果

1.training dataset(训练集)
训练集(Training Dataset)是用来训练模型使用的

2.validation dataset(验证集)
当我们的模型训练好之后,我们并不知道他的表现如何。这个时候就可以使用验证集来看看模型在新数据(验证集和测试集是不同的数据)上的表现如何。同时通过调整超参数,让模型处于最好的状态。

验证集的主要作用:
-
评估模型效果
-
调整超参数,使得模型在验证集上的效果最好
验证集不像训练集和测试集,它是非必需的。如果不需要调整超参数,就可以不使用验证集,直接用测试集来评估效果。
验证集评估出来的效果并非模型的最终效果,主要是用来调整超参数的,模型最终效果以测试集的评估结果为准。
3.test dataset(测试集)
当调好超参数后,通过测试集来做最终的评估。

通过测试集的评估,我们会得到一些最终的评估指标,例如:准确率、精确率、召回率、F1等。
详情见 https://easyai.tech/ai-definition/accuracy-precision-recall-f1-roc-auc/
4.如何划分数据集
-
对于小规模样本集(几万量级),常用的分配比例是 60% 训练集、20% 验证集、20% 测试集。
-
对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。
-
超参数越少,或者超参数很容易调整,那么可以减少验证集的比例,更多的分配给训练集。
4.1 三种主流的交叉验证法

4.2 留出法(Holdout cross validation)
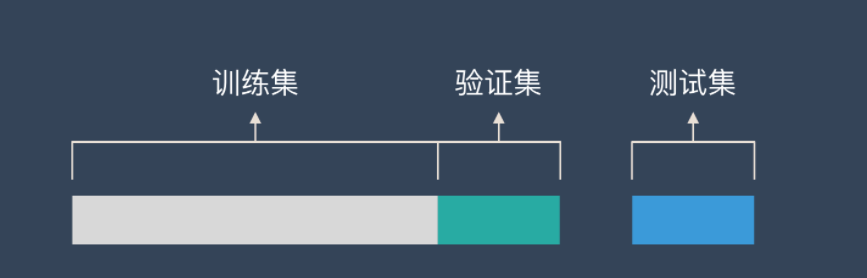
按照固定比例数据集静态的划分为训练集、验证集、测试集
4.3 留一法(Leave one out cross validation)
每次的测试集都只有一个样本,要进行 m 次训练和预测。 这个方法用于训练的数据只比整体数据集少了一个样本,因此最接近原始样本的分布。但是训练复杂度增加了,因为模型的数量与原始数据样本数量相同。 一般在数据缺乏时使用。
4.4 k 折交叉验证(k-fold cross validation)
静态的「留出法」对数据的划分方式比较敏感,有可能不同的划分方式得到了不同的模型。「k 折交叉验证」是一种动态验证的方式,这种方式可以降低数据划分带来的影响。具体步骤如下:
-
将数据集分为训练集和测试集,将测试集放在一边
-
将训练集分为 k 份
-
每次使用 k 份中的 1 份作为验证集,其他全部作为训练集。
-
通过 k 次训练后,我们得到了 k 个不同的模型。
-
评估 k 个模型的效果,从中挑选效果最好的超参数
-
使用最优的超参数,然后将 k 份数据全部作为训练集重新训练模型,得到最终模型。
k 一般取 10 数据量小的时候,k 可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。 数据量大的时候,k 可以设小一点。

本文主要参考自:https://easyai.tech/ai-definition/3dataset-and-cross-validation/